1. 摘要
传统的强化学习目标是最大化累积奖励函数。本文提出一种强化学习方法,目标改为同时最大化多个伪奖励函数,相当于增加了辅助目标。
奖励信号有时是难以观测的,稀少的。即使奖励信号很频繁,运动传感器数据也包含大量其他可能存在的学习目标。本文的目的是预测和控制运动传感器数据的特征,将它们当作强化学习的伪奖励信号进行训练(换句话来说,就是通过这些伪奖励信号的训练,改变网络的特征提取)。直觉上,如果智能体能够预测和控制它未来的经历,很容易实现一个长远的复杂的目标。
本文通过多个不同伪奖励信号对策略和状态函数进行学习,并进行一些辅助预测使得智能体侧重于任务的关键环节。本文采用了一种经验重放机制,主要重放包含奖励事件的一系列经验。为了让伪奖励信号和辅助预测影响到基础决策,本文共享一个 CNN 和 LSTM 网络。本文并没有直接利用这些伪奖励信号所对应的策略,而是作为辅助目标来学习一个更有效的表示(representation learning)。(换句话来说,这些伪奖励信号学习出来的策略并没什么卵用,只是他们学习的过程会影响到底层网络的特征表示的学习)
本文对提出的算法起了一个名字:UNREAL(UNsupervised Reinforcement and Auxiliary learning),以下简称 UNREAL 算法。这个 unsupervised 强调的是所有辅助任务的训练都不需要借助环境的额外信号来监督。(但是后面用到了过去的经验来进行监督学习。)
2. Auxiliary tasks
UNREAL 方法定义了辅助任务,并结合到强化学习的框架中。UNREAL 的架构图如下:
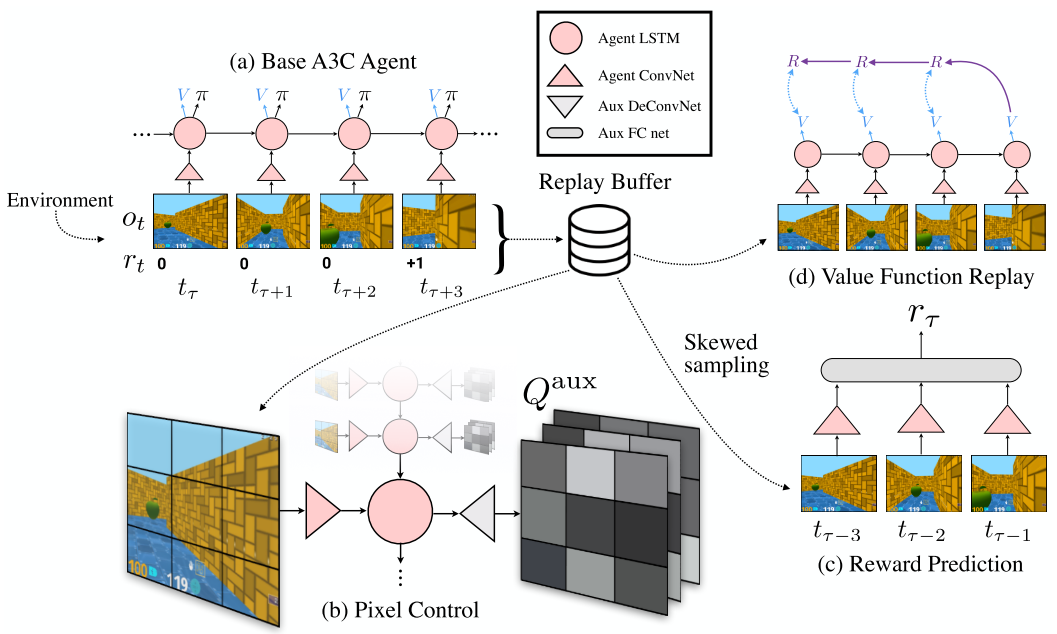
2.1 Auxiliary control tasks
辅助控制任务在文中的定义为伪奖励函数。定义辅助控制任务 $c$ 为奖励函数 $r^{(c)} : \mathcal{S} \times \mathcal{A} \rightarrow \mathbb{R}$,其中状态空间 $\mathcal{S}$ 包括观测历史、奖励以及智能体自身的状态。
假设给定辅助控制任务集合为 $\mathcal{C}$,令 $\pi^{c}$ 为辅助控制任务的策略,$\pi$ 为基础任务的策略,则整体目标定义为最大化基础任务和所有辅助任务的性能:
其中 $R_{1:\infty}$ 表示策略的折扣累计回报,$\theta$ 是策略 $\pi$ 和所有辅助策略 $\pi^{(c)}$ 的参数集合。通过共享 $\pi$ 和 $\pi^{(c)}$ 的部分参数,算法必须平衡好全局奖励 $r_t$ 和辅助任务的奖励。
为了有效地同时对多个辅助控制任务进行训练,本文提出应该采用 off-policy 强化学习方法。本文采用的是 value-based 的强化学习方法:n-step Q-learning 。对于每个辅助控制任务,定义目标函数如下:
本文定义的辅助奖励函数主要由以下两种类型:
- Pixel changes 。视觉感知流发生变化通常对应某些重要事件的发生。本文通过训练独立的策略来最大化图像输入流每个单元(大小为$4 \times 4$)的像素变化,作为一个辅助控制任务。(像素控制辅助任务)
- Network features 。由于神经网络可以提取环境的高级特征,这对于智能体的控制而言是有用信息。因此本文神经网络的每个隐藏单元的激活状态作为辅助奖励,尽可能在某一指定的隐藏层中激活每个单元。(特征控制辅助任务)
在架构图中可以看到基础策略 $\pi$ 和像素控制辅助策略共享了底层的卷积网络和 LSTM 网络。在图 (b) 中可以看到,辅助网络的输出是 $Q^{aux}$,大小为 $N_{act} \times n \times n$ 的张量,$Q^{aux}(a,i,j)$ 表示对输入图像的第 $(i,j)$ 个单元,采用动作 $a$ 之后,像素的变化期望值。辅助网络是一个反卷积网络。
对于特征控制,针对第二层卷积层($32 \times 9 \times 9$ 的特征图谱),同样采用反卷积网络作为辅助网络,输出 $Q^{aux}$ 。
其实文中最后只用了像素控制辅助任务。
2.2 Auxiliary reward tasks
为了学习到使奖励最大化的策略,智能体需要有能力识别产生高回报的状态。但是很多环境的奖励信号都是稀疏的,这意味着训练可以识别高回报状态的特征提取器需要很长时间。为了解决奖励稀疏的问题,同时不给策略和状态的学习引入偏差,本文提出奖励预测的概念。
奖励预测也是一种辅助任务。给定历史状态的上下文(一个序列的连续观测值),奖励预测辅助任务可以给出即时奖励的预测。和状态值估计不同,奖励预测需要估计的是回报值,并只将估计的回报值用于智能体的特征塑形(feature shaping),这样就不会给数据分布带来偏差,即不会给策略和状态函数带来偏差。特征塑形是指。。。。
为了训练一个奖励预测器,从策略 $\pi$ 的经验池中抽取状态序列 $S_\tau = (s_{\tau-k},s_{\tau-k+1},\cdots,s_{\tau-1})$ (预测目标就是这个序列的真实奖励值)。抽样时,尽量使得零奖励和非零奖励的概率大致相等。为了对奖励预测器进行训练,定义目标损失函数 $\mathcal{L}_{RP}$,采用的是多类别交叉熵分类损失函数,类别是 (zero, positive, or negative reward)。采用均方根误差函数其实也可以。
训练网络是策略和状态网络的 CNN 层加上一个简单的前向反馈网络。如图 (c) 所示。输入是状态序列 $S_\tau$(从图中来看,主要是连续的三帧图像)。
通过奖励预测这种方式影响的特征表示会被基础策略的 LSTM 网络共享,因此能够让策略学习得更有效率。
2.3 经验回放
为了执行辅助奖励预测,本文将经验回放池简单地分成两个子集,一个是有奖励的子集,另一个是无奖励的子集。两个子集的回放概率相等。这意味着本身稀少的带有奖励的状态被过采样,可以被视为一种优先经验回放机制。
本文同时采用经验回放池来执行状态函数回放。状态函数回放的意义是指输入近期的历史连续状态序列,通过网络输出额外的状态函数值估计。这与基础策略的状态值函数区分开,基础的状态值函数的输入的当前的状态,而状态回放函数输入是近期的历史连续状态序列。如图 (d) 所示。这种经验回放不需要进行划分。
经验回放同时也用于其他辅助任务的训练,例如 2.1 节中的 $Q^{aux}$。辅助任务的经验回放通常是采样最近的经验。
3. UNREAL 算法
UNREAL 算法的主体是 A3C 算法,借助于并行异步强化学习框架,提高样本效率和稳定性。同时采用 RNN 网络对完整的历史经验进行编码,可以更好地学习到环境的特征。
UNREAL 的损失函数可以表示为四种损失函数的简单结合形式:
$\mathcal{L}_{A3C}$ 表示 A3C 损失,$\mathcal{L}_{VR}$ 表示状态回放函数损失, $\mathcal{L}_{PC}$ 表示辅助控制函数损失损失,$\mathcal{L}_{RP}$ 表示辅助奖励预测损失。$\lambda_{VR}$、$\lambda_{PC}$ 、$\lambda_{RC}$ 是相应的权重。
$\mathcal{L}_{A3C}$ 使用的是 on-policy;$\mathcal{L}_{VR}$ 需要使用经验回放池近期的历史状态序列和 A3C 估计的状态值;$\mathcal{L}_{PC}$ 通过经验回放以及 n-step Q-learning 方法训练;$\mathcal{L}_{RP}$ 需要使用重新划分的经验回放池。
4. 工程设置
- 输入:连续四帧的 $84 \times 84$ RGB 图像
- 卷积层:前面两层都是卷积层。第一层有 16 个 $8 \times 8$,步长为 4 的滤波器。第二层有 32 个 $4 \times 4$ ,步长为 2 的滤波器。
- 全连接层:总共有 256 个单元。
- 激活函数:以上三层均采用 ReLU 激活函数。
- LSTM 层:带 forget gates,256 个单元。输入为 CNN 编码的观测值,以及先前的动作和当前的奖励。
- 策略函数和状态函数:都是 LSTM 层的线性映射。
- episode length:20 个时间步长。
- 像素控制辅助任务:
- 将图像中间的 $80 \times 80$ 的区域分成 $20 \times 20$ 的方格,每个格子为一个 $4 \times 4$ 的单元。辅助任务的即时奖励定义为每个单元的平均像素和上一帧对应单元的平均像素的绝对值。
- $Q^{aux}$ 产自 LSTM 网络的输出和反卷积网络。首先将 LSTM 的输出通过全连接网络,ReLU 激活函数,映射为 $32 \times 7 \times 7$ 的特征图。然后利用反卷积层,带有 $N_{act}$ 个,大小为 $4 \times 4$,步长为 2 的滤波器,将 $32 \times 7 \times 7$ 的特征图映射为独立的状态值张量和优势值张量(采用 dueling DQN 中的技术),最后合并为 $N_{act} \times 20 \times 20$ 的 $Q^{aux}$ 。
- 特征控制辅助任务:
- 对于第二层卷积层的输出($32 \times 9 \times 9 $),同样也采用反卷积网络映射为 $Q^{aux}$ 。
- 奖励预测任务输入为三个连续的观测值。经过agent 的 CNN 编码输出后,这三个输出值连接一个 128 个单元的全连接网络,采用 ReLU 激活函数,最后是 softmax 层,输出三个概率值(正奖励、负奖励、零奖励的概率)。$\lambda_{RP}$ 设置为 1。
- 状态回放函数采用长度为 20 的历史连续状态序列。
- 经验回放池存储最近 2k 个经验(观测值、动作、奖励值)。
- 采用 32 个并行线程,RMSprop 优化算法,学习率从 0.0001 和 0.005 之间 log 均匀采样。